
NEURAL NETWORKS (NN)
OVERVIEW:
Neural networks consist of modern algorithms that can recognize patterns and learn from these patterns. Neural networks were influenced by the principles of cognition inherent in the human brain; whereas humans excel at understanding patterns, Neural networks are adept at recognizing complex relationships in larger sets of unstructured data, like text. For the purposes of this project, a neural network was used to explore the subtle signals that differentiate sentiments in online content around regulation and misinformation.
In language, many meanings are implicit, constructed in tone and the arrangement of words and phrases with subtle shades of meaning. Traditional, rule-based approaches often encounter challenges with these subtleties. Neural networks, on the other hand, are designed to respond to such problems with an entirely different approach, as neural networks look for patterns within the structure of the data, and note combinations of words, repeated expressions, or textual signals that denote an emotional position or theme, regardless of rules and other conventions.

The type of neural network used in this application is a convolutional neural network (CNN). Though CNNs have typically been applied to image processing tasks, they also demonstrated very good performance when applied to text classification tasks. CNNs can be used where multiple filters can be slid across a sequence of words to find important phrases or chunks of text which display strong feelings or common themes. Filters are similar to lenses and are usually used to view small areas of interest to find meaningful patterns or instances.In order to optimize the pattern recognition process, multiple filters of varying sizes were employed.
This allowed for a greater amount of language cues captured within the network; some cues were two or three words in length, while others were captured in longer phrases. Once the signals had been captured, the network combined each layer's outputs and produced a sentiment prediction for each text excerpt.This setup allowed each article to be classified into one of four sentiment categories; anti-regulation, neutral, weakly pro-regulation, or strongly pro-regulation.
Each category reflects the overarching tone or stance taken in the sample's content and ultimately provides a way to measure how frequently the various stances were presented through misinformation-related texts.Neural networks in this project demonstrate their potential for automated text analysis. Learning directly from real language, these systems offer an effective and efficient way to monitor public discussion, track trends in emotional responses, and develop a better idea of the online narratives being developed. As content increases in the digital space, the value of tools like these will become essential for researchers, policymakers, and platforms.
DATA PREP:
The data needs to be prepared in a manner that is indubitable for the system to learn from the data to learn. In our project, the source data was text content from articles and news about misinformation and regulation responses. Each text sample included a sentiment label that described the general attitude toward regulation.
First, we performed data preparation through cleaning and lemmatization. In linguistics, lemmatization is a process of reducing the words to their base form, while applying meaning, to achieve consistency and make the text easier to analyze. We used the cleaned and lemmatized data for input into our modeling process.
The texts were assigned to one of four sentiment labels:
-
Anti-regulation
-
Neutral
-
Weakly pro-regulation
-
Strongly pro-regulation
These sentiment labels were used for supervised learning and allowed the model to develop an ability to generalize to text it has never seen using labeled input data.
The labeled data consisted of two separate sets:
Training Set: 843 samples were used to teach the neural network
Test Set: 211 samples were held out to evaluate how well the model does with new unseen content.
Before Transformation:

After Transformation:

Training Data (Features):

Training Data (Label):

Testing Data (Features):

Testing Data (Label):

CODE:
Link to the code of Neural Networks (NN) : https://github.com/saketh-saridena/TextMining_Project
RESULTS:
Following completion of the training of the neural network on the labeled text data, the model was assessed on previously unseen examples to evaluate the performance. The intent was to evaluate how well the system would be able to classify the tone or stance in new text cases compared to patterns learned when it was being trained.
The overall performance on the final test was about 49.29%, which means the model correctly identified the tone in nearly 50% of the new cases where the tone or sentiment was not provided to the model. This shows that the model has distinct learning but also represents the complexity of working with text data from the real world, much of which can be ambiguous, is not always presented in clear terms, or is a combination of different tones.
A more representative performance data is provided via the confusion matrix. This matrix indicates how frequently the model make the correct predictions for each tone compared to the instances it confused the right terminology with a different tone title. Indicatively, the model performed best with anti-regulation tone, where the model predicted anti-regulation, for precision and recall, higher than the alternative categories in this case.
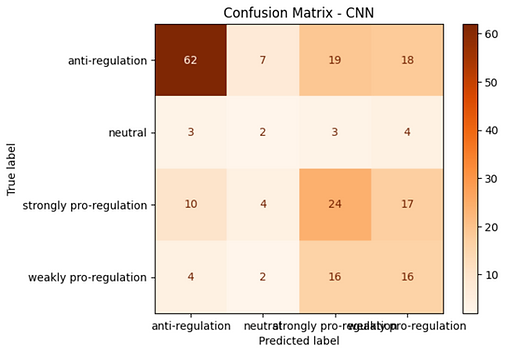
The Classification Report gives more information as well. It shows precision (accuracy of positive predictions), recall (how likely all actual positive instances were found), and the F1-score (a moderate value of both recall and precision) for each of the four sentiment classes. The model had the most success when identifying anti-regulation articles, achieving a F1-score of 0.67. This implies that the content against regulation had more distinct learning patterns available for the model to learn from.

Despite the challenges, the use of a multi-layer convolutional network allowed the system to detect patterns in text such as short phrases, expressions, and tone indicators. This reinforces the idea that different viewpoints toward regulation tend to be communicated using distinctive language—making it possible to classify such texts with moderate accuracy using automated methods.
CONCLUSION:
Neural networks provide the basis for the general idea of detecting and analyzing language, indicating that a tone can be established for the text. The work has challenges in achieving depth and accuracy in the measures used to ascertain sentiment across categories, but the model did well to meet the task for probably only the most strong-worded opinions.
The model captured a consistent verbal cue associated with anti-regulation language. Overall, these data suggest that yet again some opinions are clearly communicated using an identifiable language choice: meaning some opinions are language-wise, a little more likely to be acted on. Overall, it was harder for the model to classify the more subtle or neutral expressions, as this tends to occur in most general communication.
Overall, this experience sifted some supportive confidence in neural networks for text analysis at-scale. Still, even at a performance below that expected from classic research questions this was sufficient to offer conclusions about the tone of the reporting. Even a moderate prediction of some tone reveals that these systems will provide greater insights into how public discourse is framed and the tone of different sentiments. It is to be imagined that appropriately situated models of the data and process would produce a reliable mechanism for monitoring content and iteration in social patterns of meaning-making across time or contexts.
Github Repo (Code and Data): https://github.com/saketh-saridena/TextMining_Project